
[ECCV'24] SwiftBrush v2
Make Your One-step Diffusion Model Better Than Its Teacher
Highlights
In this paper, we aim to enhance the performance of SwiftBrush, a prominent one-step text-to-image diffusion model, to be competitive with its multi-step Stable Diffusion counterpart. Initially, we explore the quality-diversity trade-off between SwiftBrush and SD Turbo: the former excels in image diversity, while the latter excels in image quality. This observation motivates our proposed modifications in the training methodology, including better weight initialization and efficient LoRA training. Moreover, our introduction of a novel clamped CLIP loss enhances image-text alignment and results in improved image quality. Remarkably, by combining the weights of models trained with efficient LoRA and full training, we achieve a new state-of-the-art one-step diffusion model, achieving an FID of 8.14 and surpassing all GAN-based and multi-step Stable Diffusion models.
Supplementary Video
Qualitative Results



8k wallpaper of a mysterious beautiful kunoichi ninja wearing
black, red, and gold jewelry in the streets of a dark snowy
town in russia, by artgerm, intricate detail, trending on
artstation, 8k, fluid motion, stunning shading, by wlop

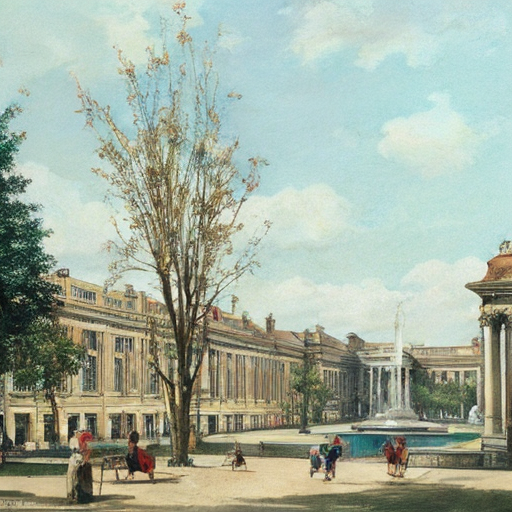


A architectural drawing of a new town square for Cambridge
England, big traditional musuem with columns, fountain in
middle, classical design, traditional design, trees






A meandering river through a picturesque anime countryside, in
the style of Makoto Shinkai's breathtaking landscapes, with
attention to natural beauty




Abstract art style, abstract painting, pulsating quasar that
is sending an enormous amount of energy throughout the
universe





A laughing cute grey rabbit with white stripe on the head,
piles of gold coins in background, colorful, Disney Picture
render, photorealistic








a cute kitty, (extremely detailed CG unity 8k wallpaper),
professional majestic impressionism oil painting





Photo of an elderly man from Siberia with a full beard during
a cold day. The sunlight beams onto his face, emphasizing the
ice that has formed from his breath in his beard. He exudes a
feeling of satisfaction. Portra 800. Analog light leak.









Portrait of a woman looking at the camera
Quantitative Results
| Method | NFEs | FID↓ | CLIP↑ | Precision↑ | Recall↑ |
|---|---|---|---|---|---|
| StyleGAN-T† | 1 | 13.90 | - | - | - |
| GigaGAN† | 1 | 9.09 | - | - | - |
| SDv1.5 (cfg = 3)† | 25 | 8.78 | 0.30 | 0.59 | 0.53 |
| SDv2.1 (cfg = 2)‡ | 25 | 9.64 | 0.31 | 0.57 | 0.53 |
| SDv2.1 (cfg = 4.5)‡ | 25 | 12.26 | 0.33 | 0.61 | 0.41 |
| SD Turbo‡ | 1 | 16.10 | 0.33 | 0.65 | 0.35 |
| UFOGen† | 1 | 12.78 | - | - | - |
| MD-UFOGen† | 1 | 11.67 | - | - | - |
| HiPA† | 1 | 13.91 | 0.31 | - | - |
| InstaFlow-0.9B‡ | 1 | 13.33 | 0.30 | 0.53 | 0.45 |
| DMD† | 1 | 11.49 | 0.32 | - | - |
| DMD2† | 1 | 8.35 | - | - | |
| SwiftBrush | 1 | 15.46 | 0.30 | 0.47 | 0.46 |
| Ours | 1 | 8.77 | 0.32 | 0.55 | 0.53 |
| Ours* | 1 | 8.14 | 0.32 | 0.57 | 0.52 |
Qualitative Comparison
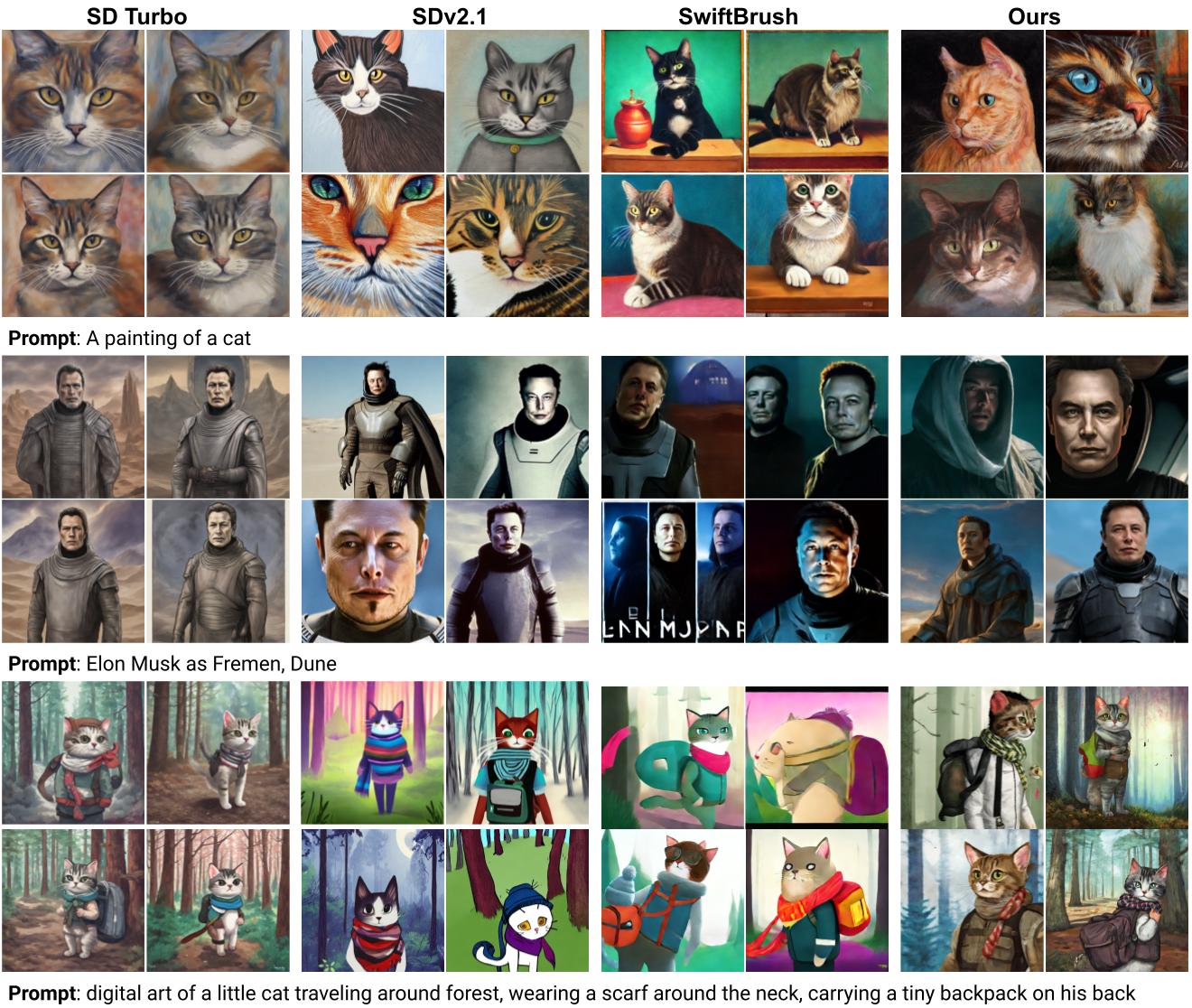
More Qualitative Results

































Acknowledgement
We give special thank to
Latent Consistency Model's authors for the awesome webpage. We also thank the HuggingFace
team for the diffusers framework.
